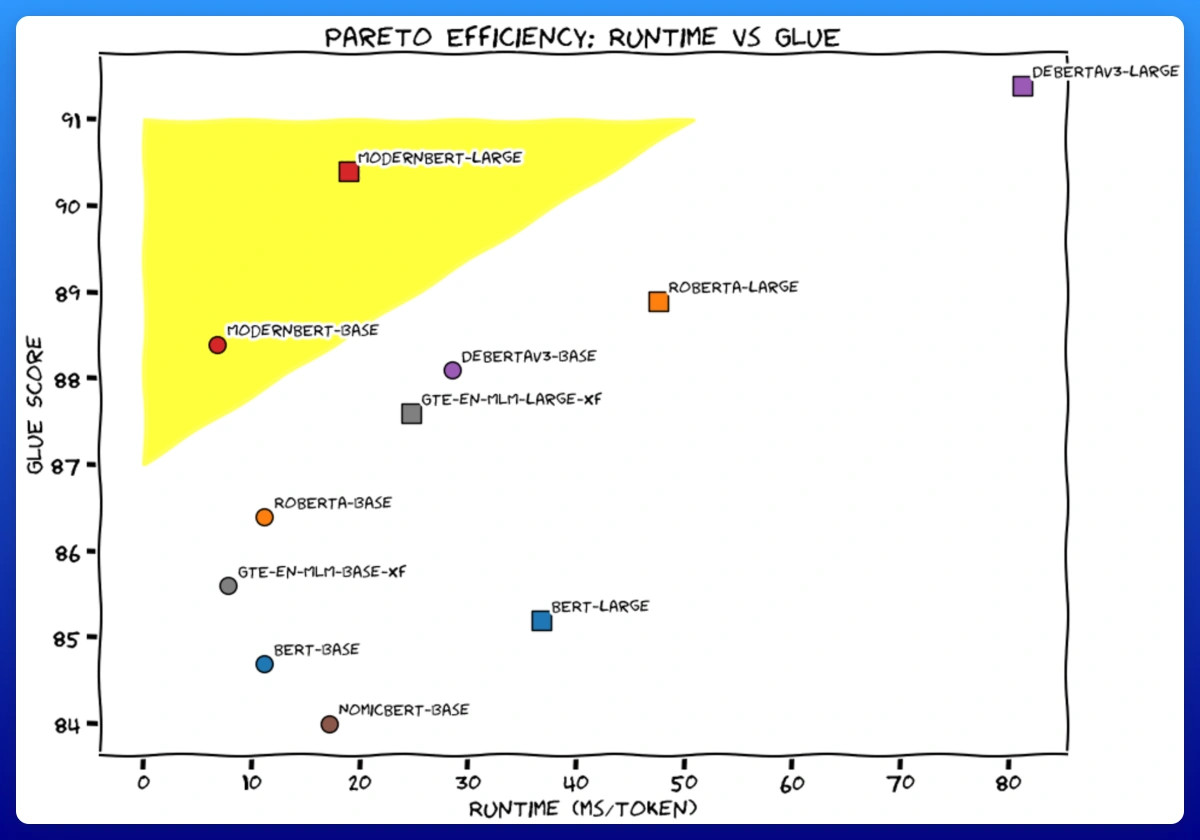
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
The winner is '.translatesAutoresizingMaskIntoConstraints', with 42 characters in a single token. OpenAI really values iOS development I guess 😅
As it turns out: It's one of the longest tokens without special characters. When considering special characters, the top ones look like this.
Let’s collaborate on democratizing insights from tabular data in Amsterdam! ✨
PhD directions: 1) fundamental techniques for tabular foundation models, 2) reliable mechanisms for AI-powered tabular data analysis.
Sharing w/ friends appreciated! ⬇️
Logitech forgot to renew its server certificate, so now my mouse scrolls in the opposite direction, and I'm unable to move between windows. What a time to be alive.
IRLab Amsterdam made it to Bluesky! Go give @irlab-amsterdam.bsky.social a follow for all things RecSys, IR, RAG, Conv AI, etc!
A read that resonates. I keep coming back to the thought of how curation by algorithms fits into this idea of the web. If someone has some good reads on this, let me know! The group at serendipityengine.be is one great example imo.
Today's funny tokenization realization: The GPT4 tokenizer has 1 single token for the entire lower- and uppercase alphabet.
Congratulations dr. Zihan Wang! It was an honor to be your paranymph.
🚨 PhD position alert! 🚨
I'm hiring a fully funded PhD student to work on mechanistic interpretability at @uva-amsterdam.bsky.social. If you're interested in reverse engineering modern deep learning architectures, please apply: vacatures.uva.nl/UvA/job/PhD-...