at://
/
app.bsky.feed.post
/
3lbvklietz227
sign in
All
4
Record
2
Post
1
PostEmbed
1
Post
by @danabra.mov
PostEmbed
by @danabra.mov
Record
by @jimpick.com
Record
by @atsui.org
+ new component
Post
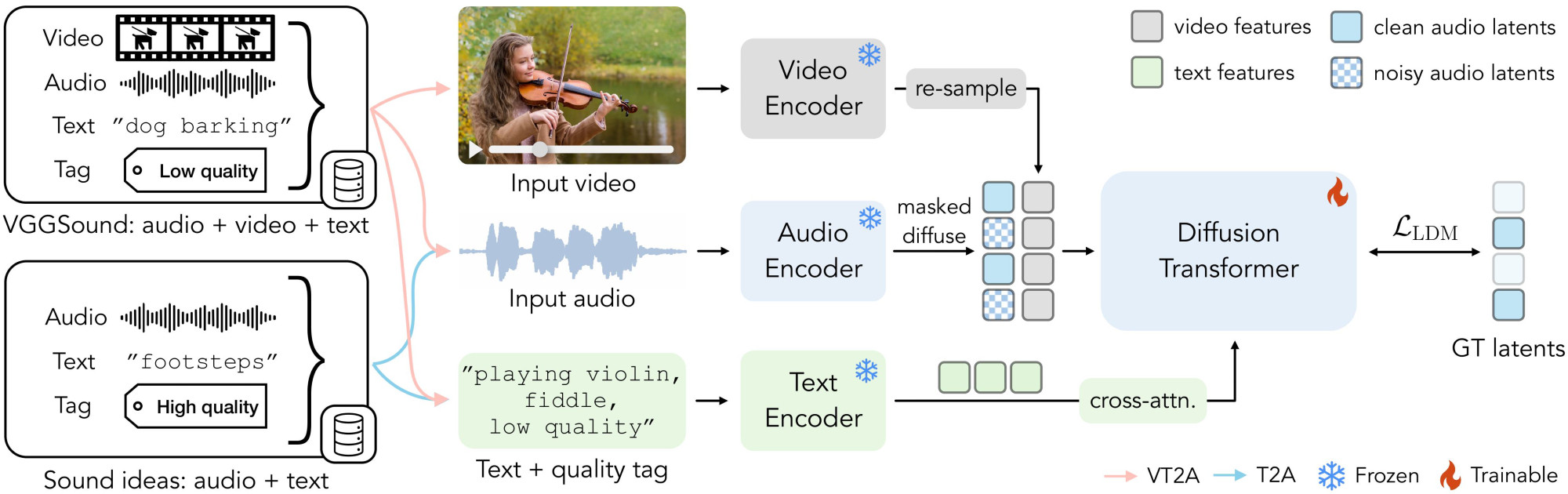
We jointly train our model on high-quality text-audio pairs as well as videos, enabling our model to generate full-bandwidth professional audio with fine-grained creative control and synchronization.
Nov 27, 2024
Ziyang Chen